Pablo Lamelas –PROTECTED TAVR study was presented in TCT 2022, bringing more discussion than ever for the use of Sentinel (cerebral embolic protection, CEP) during TAVR procedures. Many key opinion leaders posted their perspectives on social media, which are diverse: some state we should keep using CEP, while others say we should not.
Among all the opinions, the ones that caught my eye were “this is a negative trial”, “we should not trust secondary outcomes results”, “the small effect does not justify its use”, and “the argument ‘what if your family need a TAVR’ is not valid”. In this commentary, I will discuss those statements in detail and later provide my personal approach to this topic.
First section: Expanding some statements from social media
Is PROTECTED TAVR a negative trial?
What is a negative trial? There is a popular belief that without a statistically significant difference in the primary outcomes is equal to a negative trial. However, a true negative trial is one in which 95% confidence intervals (the uncertainty due to random error around the point estimate) exclude a minimally important benefit (see “Examples” from Figure 1, adapted from “Clinical Epidemiology” Sackett, Haynes, Guyatt).
What is a minimally important benefit? This could be defined as the minimum benefit that patients would perceive a benefit to justify the use of the intervention (note: this is not equivalent to a minimally important difference from patient-reported outcomes, that’s another story). The minimally important benefit is mainly based on the importance of the outcome for patients, balanced with potential harms and inconveniencies. The more important the outcome and the lower risk of relevant harm, the lower the minimally important difference.
In this case: how much does stroke/disabling stroke difference in favor of CEP vs no use of CEP? 20 per 1.000 treated (2% absolute difference, NNT 50)? 10 per 1.000 treated? 5 per 1.000? per 1.000? I don’t know, maybe we should ask our patients?
Maybe, because there is no relevant harm/risk for patients receiving CEP, any perceivable risk reduction would be acceptable for patients regardless of how small may look. This mainly applies to patients with health coverage, for which costs are not placed into the equation. Patients who need to pay extra from pocket to receive CEP during TAVR may request a higher likelihood to be effective.
How do we determine a minimally important benefit? Although this estimation may come from multiple sources, I will cite a recent one totally unrelated to cerebral protection in TAVR. We are developing a guideline for PCI vs CABG in left-main disease in Latin America. We asked the panel, composed of clinical cardiologists, cardiac surgeons, and interventional cardiologists, which is the minimally important benefit for periprocedural all-stroke for PCI vs CABG. Although this is not definitive, the current median value is 8 per 1,000 treated (-0.8% difference), NNT 125. Consider that this is all stroke, so disabling stroke is likely to be even smaller. Also, in another source for the use of “safe acute interventions,” the minimal important difference among academic neurologists ranged from 0.8% to >2%.
Let’s assume that the minimally important benefit for stroke/disabling stroke is between 0.5% (5 per 1.000 treated with CEP, NNT 200) and 1% (10 per 1.000 treated with CEP, NNT 100). Then, a true negative trial with a lower 95% CI should exclude this difference. PROTECTED TAVR reported −0.6 percentage points for all stroke (95% CI, −1.7 to 0.5) and −0.8 percentage points for disabling strokes (95% CI, −1.5 to −0.1). Figure 1 shows the results (not in scale, illustrative) relative to other plausible scenarios with their suggested interpretations.
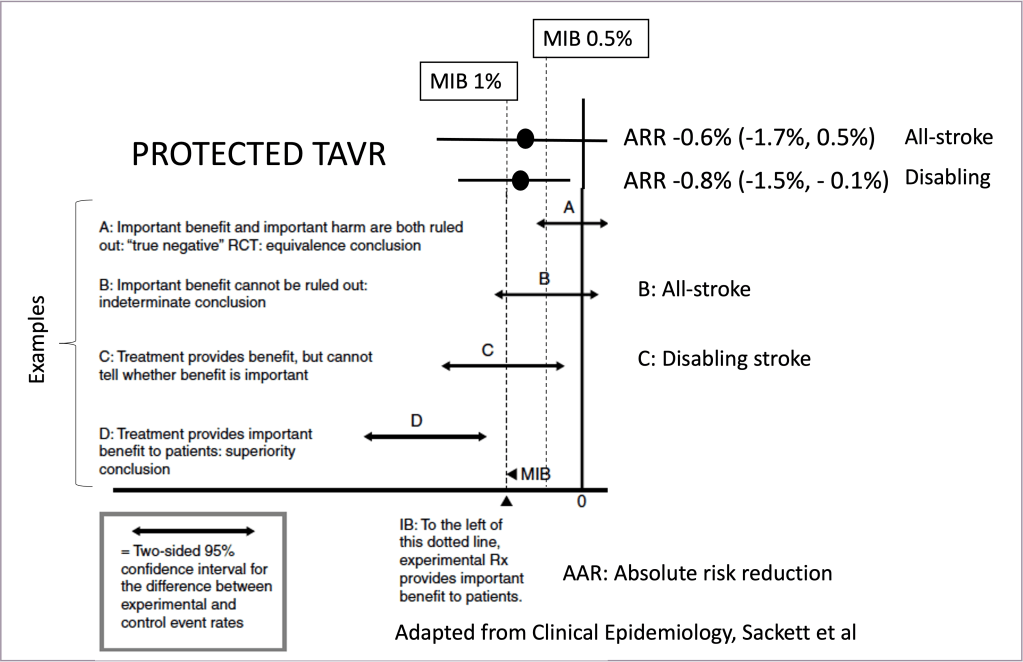
Hope that after this explanation, is crystal clear that PROTECTED TAVR is not a true negative trial, but an inconclusive trial or indeterminate result for all-stroke (scenario B) or treatment provides benefit but cannot tell if the benefit is important for disabling stroke (scenario C). Moreover, if we consider that any perceivable benefit would be accepted for patients, we may face scenario D in which there is a statistically significant benefit.
Never describe your indeterminate study as “negative” or as showing “no difference”
Dave Sackett, Father of Evidence-Based Medicine. “Clinical Epidemiology” Chapter 5
Should we trust secondary outcome results?
Why do trials have a hierarchical outcome order, ranking as primary (main study interpretation), secondary (to support the primary results), or tertiary (“hypothesis-generating” for future studies)?
Although other reasons exist (ie, guide overall design, power calculation, etc), a key one is that in a properly executed randomized trial in which the main threat is a random error (rather than a prognostic imbalance in observational studies, here dealt with randomization), doing multiple tests may induce “false positive” findings. Powering the study for a single primary outcome would provide proper statistical power for that “outcome test only”. If more tests are generated multiple testing random errors may be introduced. Tools are available to deal with this multiple testing error, beyond the scope of this commentary.
However, the current best standards of evidence-based medicine taught us that we should not rely on isolated studies results to build the best evidence to inform a decision. Rather we should consider all the best available evidence from pooled results of all eligible studies, preferably randomized trials.
In other words, is irrelevant the hierarchical order of original studies of each outcome. What is important is outcome validity (how properly the outcome was assessed, measured, and reported in each study, etc) regardless if it was a primary, secondary, or tertiary outcome in the original report/s, or if the study was powered or not for that specific outcome. The pooled estimate from “the totality of the evidence” and its certainty assessment are presented below in the second part of this commentary
The observed effects are small?
We all agree that the magnitude of the observed effect in PROTECTED TAVR (-0.6 % for all stroke and -0.8% for disabling stroke) is not large. The reported 2.9% risk seems low for a trial using systematic neurologist screening. For instance, the prior SENTINEL IDE trial reported a quite higher incidence, and real-world registries show similar (or sometimes higher) stroke risk in all-comers TAVR procedures (despite no systematic screening and higher risk patients included, so likely underreported in real-world practice).
Why is this important? Methodological point: the higher the control group risk, the larger the absolute risk-benefit. The benefit of interventions is based on absolute risk, rather than relative risk. So, are we sure that the results of PROTECTED TAVR applied in real practice will remain the same?
Randomized trials are the best tool to assess the relative treatment effectiveness between study arms (ie, estimate the best unbiased relative risk), but many times have important limitations in establishing baseline risks due to selection bias. We are all familiarized with situations in which trials fall short in statistical power because they assumed a larger control event rate based on real-world reports, or real-world reports doubling randomized trial observed events.
The reason is simple: patients enrolled in randomized trials are usually healthier than those that are not included in the overall population (few exceptions may apply). For PROTECTED TAVR, the highest stroke participants may not be included, despite trialists’ encouragement to do so. Also, centers with no-very-large TAVR experience are likely to have higher stroke rates and not participate in large trials.
So, frequently for guideline development (following the best standards, ie: the GRADE approach), we extract the relative risk estimates from randomized trials (that is the best product from trials), but baseline risks from real-world reports. This is very important since the relative risk of PROTECTED TAVR is 0.78, representing a -0.6% risk reduction for a baseline risk of 2.9%, but assuming 5% a real-world stroke risk, absolute risk reduction is -1%, NNT 100. For disabling stroke even more marked, since RR is 0.41 and a baseline risk of 3% (aligned with multiple prior reports, and could be even higher) would be a -1.8%, NNT 55.
Before we finish with benefits: Sentinel demonstrated a reduction in brain damage in prior studies. Brain damage is not only a surrogate for procedural stroke, but also for future cognitive decline. Brain damage accelerates cognitive decline in patients undergoing cardiac surgery. What information do we have about long-term cognitive decline for protected TAVR? None. The picture of actual CEP benefits is therefore incomplete.
The effect is not large enough to justify its use?
Do you know the NNT of seatbelts to prevent one death? NNT = 25,000. Despite that, I never met a person putting into question seatbelt efficacy, like requesting cars to be a couple thousand dollars cheaper for a seatbelt-less car (Disclaimer: I use and recommend seatbelts).
If this large seatbelt NNT looks surprising, follow this exercise. The baseline risk for a car accident is 1 death per 14 million miles (roughly you need to drive 560 times the circumference of the earth at the equator). Now, think about how many deaths are prevented with seatbelts, how many high-impact accidents make a fatal accident into a non-fatal one? Well, hopefully now you contemplate that the efficacy of seat belts is small, in absolute risk. However, since it has no relevant harm people usually do not put into question its applicability despite its marginal benefit, or increased fabrication costs.
If the observed effect on stroke or disabling stroke of CEP is trivial, small, moderate, or large, is a judgment that should come mostly from patients, as we discussed before. Considering that 1) patients’ weight stroke is the most important non-fatal outcome, and in some reports even considered worse than death, 2) there are no major clinical harms to patients with CEP use, I bet most patients will be willing to receive CEP despite very small anticipated effects. Regarding costs, the next point covers them.
“If your family needs TAVR, would you use CEP” argument is valid?
CEP with Sentinel has virtually no major clinical adverse events, beyond a marginal increase in contrast, radiation, and procedural duration (likely non-important for most patients, but we may also have to ask them!).
The “what if you/your family…” argument is usually criticized on social media since is unrealistic, and I agree with that. But, this argument is basically stating: if costs are not a problem, does the observed balance between efficacy vs adverse effects justify the use of CEP? Most TCT panelists said yes, and probably most properly informed patients would also prefer CEP during their TAVR.
Some parts of the disagreement may be what we should tell a patient to be considered properly informed. For me, demonstrated reduction in brain damage (surrogate outcomes, SENTINEL IDE among others), not conclusive but suggestive of a lower risk of stroke (imprecision in estimates), no data about long-term cognitive function, and no major clinical harm to patients.
Still, the current standard of evidence-based practice includes resource use and costs in decision-making. We cannot practice medicine ignoring this. How much cost the system can spend on cerebral protection? See the second part of this commentary.
In summary: PROTECTED TAVR is not a true negative trial. We should use the totality of the evidence of all patient-important outcomes regardless of primary/secondary outcome labeling. The problem of random error is better handled by meta-analysis, and if imprecision is still a problem then the certainty of the evidence is downgraded as appropriate. If the treatment effect is negligible, trivial, small, or whatever, needs judgment and mainly input from patients. If costs are justified or not, would depend primarily on how much value patients put into the observed effects and resource availability.
Second section: my personal way to approach this controversy (and also others): Following the 3 principles of Evidence-Based Medicine
It would be easier for me to just say what I think in a line but prefer to expand the logic behind this. In this more transparent way, readers can understand its fundamentals and recognize points of agreement or disagreement. Please let me know any positive o negative feedback about this perspective.
Do we practice Trial- or Evidence-based medicine?
Every year new large (or larger) trials of certain topics are published, and we tend to give quick conclusions based solely on this new trial, name it: trial-based medicine. This violates the first principle of evidence-based medicine, which states we should consider all the best available evidence, which of course goes beyond PROTECTED TAVR. Then, to better judge if Sentinel CEP reduces stroke or not we should pursue a meta-analysis of all available randomized trials about this research question.
Methodological note: Many readers may consider that meta-analyses have a bad reputation, due to many unnecessary/repeated/redundant publications and frequently not based on high-quality systematic reviews (selection bias of included studies), which I agree with. But meta-analysis is the standard tool to combine in a single estimate the body of the evidence from different trial results, our best tool to deal with random error. To my knowledge, if meta-analysis across available trials should or not be used to develop high-quality recommendations is not under debate in the clinical epidemiology field.
So, this is how it looks like the updated meta-analysis of (A) all-cause stroke and (B) disabling stroke. This was done by myself using data from prior systematic reviews (P: TAVR, I: Sentinel, C: no Sentinel) adding the PROTECTED TAVR results.

Main results show for Stroke RR 0.75 [0.52, 1.08], disabling stroke RR 0.41 [0.20, 0.86]. As you can see, the sum of all strokes in these smaller trials represents 32% of the total stroke events/weight, not bad! Reinforcing the point of considering all the available evidence. Still, results are mostly driven by PROTECTED TAVR.
Next step: Are the results credible? (this section is tough but necessary)
The second principle of evidence-based evidence: Not all evidence is created with equally, we need to assess it. Once we have the body of the evidence summarized by the forest plot, is time to assess how certain are these estimates. Nothing better than GRADE for this.
Disclaimer: Although a formal GRADE-based certainty of evidence requires a process which I will not undertake alone now (ideally by more than one unconflicted methodologist, I do have conflict of interests and I’m alone!), will try to give a glance of how it would likely look like doing my best to remain objective about this topic. So, take the following assessment with caution since a formal GRADE process may differ from this present analysis. Still, I consider that a personal GRADE-guided analysis complements what is available today: the TCT panel discussion and multiple and many times discordant key opinion leaders’ perspectives in social media and other sources.
For a GRADE certainty of the evidence, we focus on 5 domains: Imprecision (random error), inconsistency (heterogeneity), indirectness (when the included studies do not represent the actual population, intervention, or outcome of interest in this case), risk of bias (typical Cochrane criteria) and publication bias (the included studies do not represent all the executed research).
What a GRADE-guided approach may show for evidence certainty? There is no relevant inconsistency/heterogeneity across studies. In terms of indirectness, most of the people included in the trials underwent transfemoral TAVR, the Sentinel device is the same, the control arm is no protection used, and the outcome is clinical stroke as VARC. Then, no important indirectness is expected.
The risk of bias assessment using the Cochrane tool in prior studies was not concerning (as per assessment in prior systematic reviews), but industry sponsor and blinding may be considered of concern. According to PROTECTED TAVR protocol, neurologists should be blinded but the manuscript, and the TCT presentation state that they were aware of the clinical record (unclear to me at least blinding status). Not sure what a duplicate expert assessment of the risk of bias would conclude about this domain, may judge no concerns or some concerns. Especially because 70 to 80% of the meta-analysis weight comes from PROTECTED TAVR. Publication bias is unlikely.
Now comes the most important domain to expand in this scenario: imprecision (random error). Many interpret that crossing the line of no-effect (RR of 1, like the all-stroke outcome in this evidence assessment) means that the tested intervention is not effective. Also, many believe that excluding the no-effect line (RR upper confidence interval is below 1, like the disabling stroke outcome in this case) means the treatment is effective. Both statements are usually incorrect (or grossly simplified). Crossing or not the no-difference line is never enough to conclude whether a treatment is truly effective enough, or not.
When assessing impresicion, the first thing we usually check is the optimal information size, which is the estimated total sample size of a single study for the observed relative risk reduction and baseline risk. The RR of all strokes was 0.75 (relative risk reduction of 25%) and baseline risk of 3.5% (note: we are using estimates from the forest plot from now on, the totality of the best available evidence). Using a regular sample size calculator, this would need a study beyond 5.700 participants, which is way over the actual randomized patients across all available studies using Sentinel: 3,506 patients.
After optimal information size assessment, we look at the confidence interval width, which in this case is quite wide for all-stroke (0.52 to 1.08). The number of total events, although not small, is 112. This number of events is unlikely to provide robust estimates for a moderate risk reduction. Therefore, this moderate (25% relative risk reduction in all-stroke) has evident imprecision that would warrant one (high to moderate) or even two (concerning from high to low) downgrading in certainty, depending on those making judgments with their corresponding justifications.
What happens with disabling stroke? The optimal information size is 2500 for a baseline risk of 1.3% and a relative risk of 0.41, and 3400 for a 50% relative risk reduction. So, the optimal information size is probably met. However, the absolute number of events is small, with just 33 disabling strokes in all existing randomized trials. Pooled estimates exclude the no-difference threshold, but confidence intervals are large. The upper confidence interval in relative risk is 0.86, which equals a -0.18 % risk difference. If we consider a trivial difference as small as -0.3%, -0.18% goes beyond it. Then, is likely that an unconflicted GRADE methodologist will downgrade at least one level from high- to moderate certainty of the evidence for this outcome. Note that with GRADE we assess certainty for each outcome, separately.
What about longer-term cognitive function? Because with GRADE we need to consider all potential impacted outcomes, and cognitive function should be on the list. This outcome was not reported in any trial due to insufficient time to measure it. One way to handle this is just to mention that there is no data, and that’s it. Another option is to consider brain damage (by MRI) as a surrogate for longer-term cognitive decline. If this is the case, we would need robust data linking embolic brain damage with longer-term cognitive function. I know that some data is there, not sure about its robustness or the ability to estimate the magnitude of cognitive decline. Someone has to research this!
Moving from evidence to a recommendation
The third principle of evidence-based medicine is: Evidence alone is never enough to generate a decision. We need to integrate that efficacy/harm evidence with other sources of evidence or domains. Among these, the ones that generate more controversy and challenge the systematic use of CEP are increased costs and their impact on health system equity.
I would love to see Dr Cohen and Dr Arnold assessment of cost-effectiveness, but issues (among others) they may encounter include, 1) true baseline stroke risk in real all-comers patients and all-comers centers (maybe higher than PROTECTED TAVR), 2) the certainty of treatment effects (mostly threatened by imprecision for both all-stroke and disabling stroke), 3) no data on other outcomes, like cognitive decline (we just have surrogacy of brain damage available, of the uncertain magnitude of translation into actual clinical events).
My conflict of interests:
Financially I received honoraria in the past as Sentinel proctoring during 2021, also honoraria to present in meetings in which my personal opinion of CEP was presented. But I feel my strongest conflict is my belief. We have been using Sentinel for some time, and occasionally (is the exception, kind of random) we retrieve large embolic material from filters, that undoubtedly would have caused brain damage and likely a stroke.
This is different than coronary thrombus aspiration, following the following logic: “This clot I retrieved must have improved my patient”. With coronary thrombus aspiration, a small efficacy was demonstrated but at the risk of increased stroke. The increased stroke rate is the main reason why routine aspiration is “Class III” today, otherwise with demonstrated small effects on CV death from meta-analysis would have a class I or IIa indication. The use of CEP does not have important clinical harm to patients. Is mainly about increased costs.
My take-home message:
We should be cautious when making quick judgments about the impact of new trials in clinical practice. I understand that being conservative is the trend in research. However, we must acknowledge the methodological aspects that make studies under-estimate the true treatment effect, like lower-than-expected events in the control group, intention-to-treat analysis, no clarity about minimal important benefit in this scenario, or no information about other benefits like cognitive decline.
We are in a situation of CEP for all or for no one, no strong subgroups were identified. CEP for all TAVRs is not going to happen today globally, based on marginal benefit (in absolute terms, NNT over 100 likely), the certainty of this estimates has relevant limitations and increased costs. However, in healthcare systems that can cover the costs, most patients and treating physicians would opt continuing or starting using CEP in all (or most) their TAVR procedures.
Everyone, including me, will be happier with more information. The UK PROTECTED TAVI study is our next step. Based on the presented information so far, our team (as well as many I consulted around the globe) will keep using CEP for TAVR with a similar approach compared to the days before TCT 2022.
Hope you found this interesting and encouraging to learn more about clinical epidemiology, evidence-based medicine, and the GRADE approach: the international standard to rate evidence certainty and develop high-quality recommendations.
